
HW a SW ekosystém
Zprovoznit a hlavně provozovat lokální AI má svá pravidla a úskalí. Ač se Tesor jádra objevují už od řady RTX 20, plné využití v oblasti AI najdete převážně v řadách GeForce RTX 40 a 50 a to hlavně díky novým FP8 instrukcím, které výrazně urychlují logické oprerace.
Hardwarové požadavky
Hlavní jádro pro RTX AI je samozřejmě grafická karta, ať už se jedná o moderní GeForce řady 50 postavené na Blackwell architektuře nebo starší řada 40. Obě karty disponují moderními instrukcemi a dostatečným výkonem, kde i karty nižších tříd jako 4070 nebo 5060 jsou schopny kvalitních a rychlých generování.
Grafická karta a VRAM
Zásadní pro běh lokálních AI je množství videopaměti (VRAM). Zatímco pro hraní her často stačí 8 GB, pro AI aplikace je to absolutní minimum. Čím větší a chytřejší modely chcete používat, tím více paměti potřebujete. Pro pohodlnou práci se většinou doporučujeme minimálně 12 GB VRAM, ideálně však 16 GB a více.
- 8 GB VRAM (GeForce RTX 4060, 3060 Ti) - Malé modely, základní generování obrázků, ChatRTX
- 12 GB VRAM (GeForce RTX 4070, 5060 Ti) - Středně velké modely, plynulé generování obrázků, komfortní práce s LLM
- 16 GB VRAM (GeForce RTX 4070 Ti Super, 5070) - Velké modely, 4K generování, multi modální použití
- 24 GB+ VRAM (GeForce RTX 4090, 5090) - Profesionální použití, největší modely, generování videí, paralelní běh více modelů

Procesor a RAM
Přestože většinu té dřiny zvládne grafická karta, procesor a systémová paměť mají stále důležitou roli. Modely často zabírají několik GB a je nutné je rychle přesouvat do VRAM. Jakmile VRAM nestačí, využívá se i RAM, což sice výrazně zpomalí výpočet, ale zajistí, aby model fungoval dál. Moderní šestijádrový až osmijádrový procesor je pro většinu AI úloh dostatečný. Co se týče RAM, počítejte s minimálně 16 GB, ideálně 32 GB.
Úložiště
Modely jsou skutečně velké. Jeden difuzní model pro generování obrázků má typicky 4 až 8 GB. Velký jazykový model může mít 10 až 30 GB. Pokud navíc chcete generovat videa z textu, potřebujete několik modelů najednou a rázem se může stát, že jen na dvou modelech jste už na 30 až 50 GB. Pokud navíc experimentujete, určitě vám jeden nebo dva modely stačit nebudou. Připravte si minimálně 100 až 200 GB a ideálně rychlý NVMe SSD, protože celý ten velký model se musí nahrát do operační paměti a rychlý disk výrazně zkracuje čas načítání.
Softwarová výbava
Co se samotných programů týče, zde už velmi záleží na způsobu a typu práce, co od AI očekáváte. Pro jednoduché vyzkoušení AI nepotřebujete nic složitého instalovat. Klíčové je mít nejnovější NVIDIA ovladače, které obsahují instrukce FP8 pro akceleraci AI modelů a podporu všech moderních funkcí.
NVIDIA App
Domovská aplikace NVIDIA je asi první místo, kam byste měli kouknout, pokud chcete AI zkusit. Najdete tam hlavně možnost udržovat ovladače aktuální a pak pár doplňkových aplikací, na kterých můžete vyzkoušet různé scénáře AI. Od NVIDIA Broadcast pro odstranění šumu z mikrofonu nebo pozadí z kamery po ChatRTX, kde si můžete vyzkoušet komunikaci s LLM dokonce nad vašimi dokumenty pomocí technologie RAG.
ChatRTX
Jedná se o aplikaci, kterou jednoduše najdete právě v NVIDIA App a která je po nainstalování ihned připravená. ChatRTX funguje jako lokální chat s LLM modely, ale umí i práci s vlastními dokumenty. Stačí vybrat složku s PDF soubory, textovými dokumenty nebo poznámkami a ChatRTX nad nimi vytvoří RAG index.
RAG (Retrieval Augmented Generation) je technika, která umožňuje AI pracovat s vašimi vlastními dokumenty. Když se AI zeptáte na něco, systém nejprve vyhledá relevantní části dokumentů a ty pak předá jazykovému modelu jako kontext. Model pak odpoví na základě vašich dat, ne jen na základě toho, na čem byl původně trénovaný.
Jednoduše nastavíte složku, kde máte soubory s dokumentací, a pak se jen stačí zeptat. ChatRTX projde celou dokumentaci za vás a najde přesně to, co potřebujete. Není potřeba pročítat sáhodlouhou dokumentaci o stovkách stránek nebo trávit hodiny hledáním správné odpovědi. Jasná rychlá odpověď, která šetří váš čas. A pokud si chcete ověřit informaci, dovede vás i na stránku, kde odpověď našel.
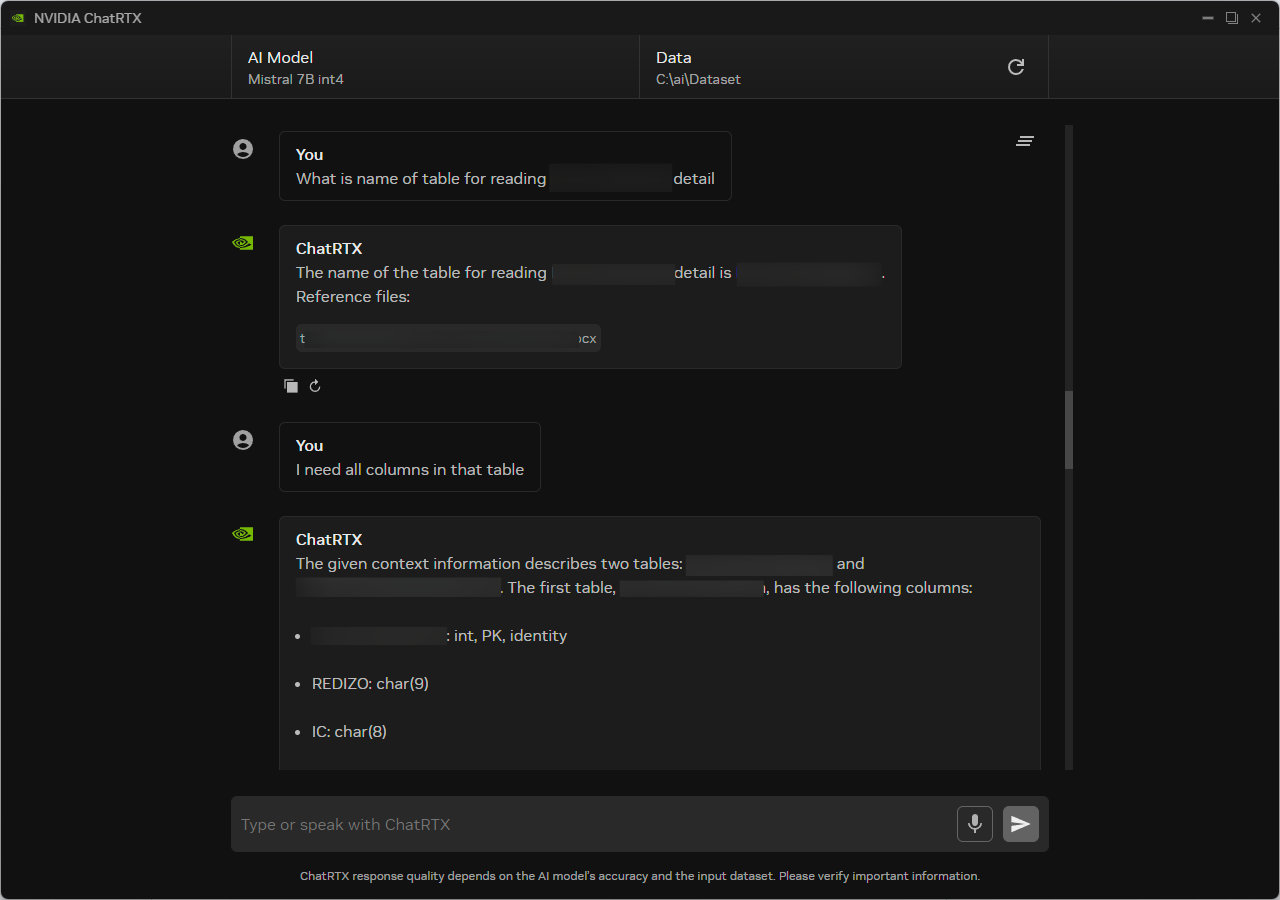
ChatRTX běží plně offline, nepotřebuje internet a vaše data zůstávají bezpečně uložená na disku. Je to ideální nástroj pro studenty, kteří chtějí rychle najít informace v učebnicích, pro programátory, kteří potřebují projít dokumentaci, nebo pro kohokoliv, kdo pracuje s velkým množstvím dokumentů a potřebuje rychlý způsob hledání informací.
Ollama
Dalším silným nástrojem pro ovládání LLM je jistě Ollama. Malý opensource program, který dokáže běžet jen čistě v příkazové řádce či příjemným rozhraní, navíc ale obsahuje robustní API, přes které jej jste schopni propojit s libovolnou aplikací a rázem se z něj stává robustní backend pro vaše aplikace.
Ať už jej chcete využít jako programovacího asistenta, chatbota nebo pro analýzu dokumentů, Ollama nabízí přímé propojení s širokou škálou nástrojů. Pro vývojáře jsou k dispozici rozšíření Continue pro Visual Studio Code a JetBrains IDE, které přidávají AI asistenta přímo do editoru kódu. Pokud preferujete grafické rozhraní, můžete využít Open WebUI s intuitivním ChatGPT stylem a podporou dokumentů, AnythingLLM s vestavěným RAG systémem nebo Msty s moderním nativním rozhraním pro Windows, macOS a Linux. Pro pokročilejší uživatele nabízí LM Studio komplexní správu modelů, zatímco díky jednoduchému REST API můžete Ollama integrovat do jakýchkoli vlastních aplikací, webových stránek nebo automatizačních nástrojů.
NVIDIA NIM
Pro pokročilé uživatele a vývojáře, kteří potřebují profesionální deployment AI modelů, nabízí NVIDIA sadu nástrojů pod názvem NIM (NVIDIA Inference Microservices). Jedná se o předpřipravené, optimalizované kontejnerizované služby pro rychlé nasazení AI modelů na jakýkoliv hardware s NVIDIA GPU, včetně GeForce RTX PC, workstationů, datových center i cloudu.

NIM mikroslužby přinášejí jednoduchost používání cloudových API s flexibilitou a bezpečností vlastního hostingu. Každá NIM mikroslužba obsahuje vše potřebné pro okamžité spuštění nejnovějších AI modelů, optimalizované inferenční enginy jako TensorRT, TensorRT LLM, vLLM nebo SGLang, standardizovanou OpenAI kompatibilní API a všechny potřebné runtime závislosti, vše zabalené v enterprise Docker kontejneru. Načtení a spuštění modelu je otázkou jediného příkazu, což významně zjednodušuje cestu od experimentu k produkčnímu nasazení.
Vývojáři mohou NIM integrovat do svých agentních AI aplikací pomocí NVIDIA AgentIQ toolkitu nebo využít předpřipravené AI Blueprints, které poskytují ready to use workflow pro RAG, agentní AI a další generativní AI aplikace. NIM tak poskytuje kompletní řešení od experimentu až po produkční nasazení enterprise AI aplikací, vše s plnou kontrolou a bezpečností lokálního prostředí na vašem GeForce RTX PC.
Jak to všechno spolupracuje
Když spustíte AI aplikaci na RTX PC, celý ekosystém spolupracuje:
- Model se načte do VRAM - SSD disk přenese gigabajty dat modelu do video paměti GPU
- Tensor Cores se aktivují - Specializovaná AI jádra převezmou výpočty
- CUDA koordinuje výpočty - Rozdělí práci mezi tisíce jader GPU pro maximální paralelismus
- TensorRT optimalizuje - Zajišťuje, že každá operace běží co nejrychleji pro vaši konkrétní kartu
- Výsledek se vrátí - Během sekund máte hotový obrázek, text nebo video
Všechno se děje lokálně na vašem PC, bez čekání na cloud, bez odesílání dat na internet, s plnou kontrolou a soukromím.